Si las muestras de cada grupo son pequeñas, estas deben satisfacer normalidad. Si son grandes (n > 30) el TLC asegura que se pueda usar la prueba t de Student.
Homocedasticidad.
No deberían haber outliers.
Prueba t de Student
¿Hay diferencias estadísticamente significativas entre las longitudes de las hojas con y sin herbivoría?
Primero verifiquemos los supuestos sobre los datos.
library(car)leveneTest(y = hojas$longitud, group = hojas$Herbivoría)
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 2 4.7381 0.009454 **
286
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Prueba t de Student
t.test(herb_si, herb_no, var.equal =FALSE)
herb_si y herb_no deben ser vectores con las longitudes de las hojas con y sin herbivoría respectivamente.
¿Cómo generamos estos vectores?
El valor p
Puede interpretarse de varias formas:
Probabilidad de que los resultados obtenidos se deban al azar.
Probabilidad de obtener los resultados observados, asumiendo que la hipótesis nula es cierta.
Probabilidad de rechazar la hipótesis nula siendo esta cierta.
Hipótesis nula e Hipótesis alternativa
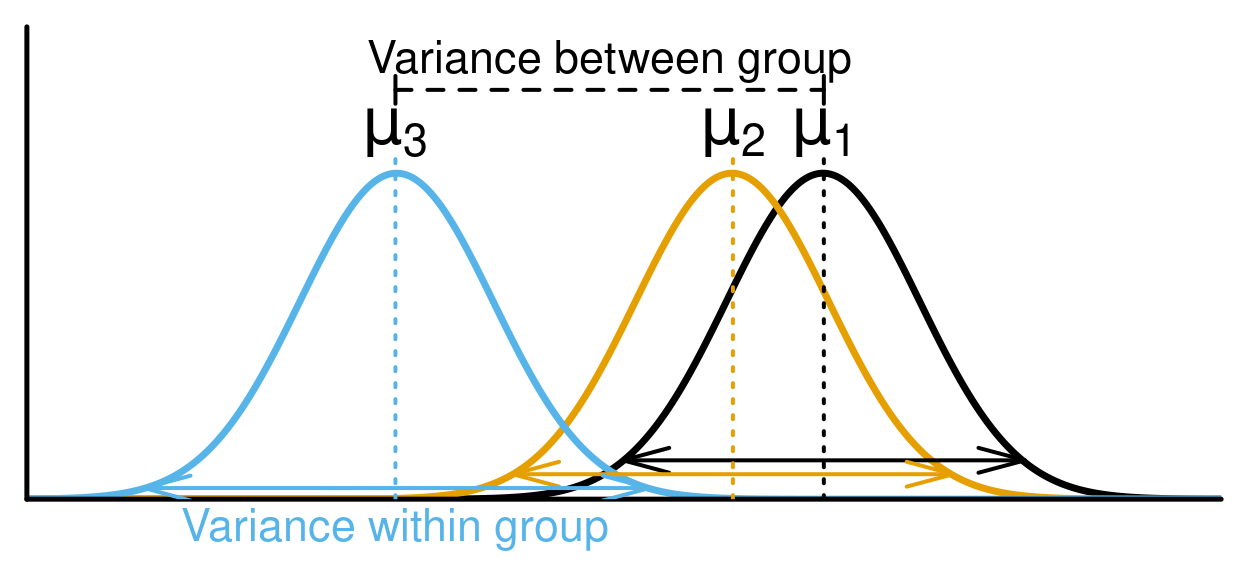
ANOVA
ANalysis Of VAriance, Análisis de Varianza
Como una prueba t de Student pero cuando se comparan las medias entre más de dos grupos.
Supuestos para hacer una ANOVA
Independencia de los datos.
Si las muestras de cada grupo son pequeñas, estas deben satisfacer normalidad. Si son grandes (n > 30) el TLC asegura que se pueda usar la ANOVA.
Homocedasticidad.
No deberían haber outliers.
¿Existirán diferencias en el ancho promedio de las hojas dependiendo de quién las midió?
ANOVA en R
res_anova <-aov(ancho ~ Científico, data = hojas)# Ver normalidad de los residualesggplot(hojas, aes(x = res_anova$residuals)) +geom_histogram() +xlab('Residuales')