| Longitud hoja | Ancho hoja | Localización | Distancia al árbol más cercano | 0-10 inflorescencias | 10-20 inflorescencias |
|---|---|---|---|---|---|
| 76 | 2 cm | 6.26508, -75.56890 | 460 | Sí | No |
| 6.2 | 3.1 cm | 6.26508, -75.56890 | 460 | Sí | No |
| 51 mm | 3.7 cm | 6° 15’ 53.424” N, 75° 34’ 5.772” W | 100 | No | Sí |
| 7.4 | 4.1 cm | 6° 15’ 53.424” N, 75° 34’ 5.772” W | 100 | No | Sí |
| 5.8 | 2.9 cm | 6.26513, -75.56926 | 320 | No | Sí |
| 81 | 3.3 cm | 6.26513, -75.56926 | 320 | No | Sí |
Análisis de datos en R
Instalando RStudio
- Ir a la página de RStudio.
- Descargar RStudio.
- Instalar RStudio con el comando:
sudo dpkg -i rstudio-2024.04.1-748-amd64.deb
Texto guía

Panorama general del trabajo en Ciencia de Datos

Datos bien ordenados
Existen tres reglas interrelacionadas que hacen que un conjunto de datos sea ordenado1:
- Cada variable debe tener su propia columna.
- Cada observación debe tener su propia fila.
- Cada valor debe tener su propia celda.

¿Por qué usar formatos abiertos y software libre de análisis de datos?
¿Se están cambiando los nombres de genes humanos por culpa de Excel?
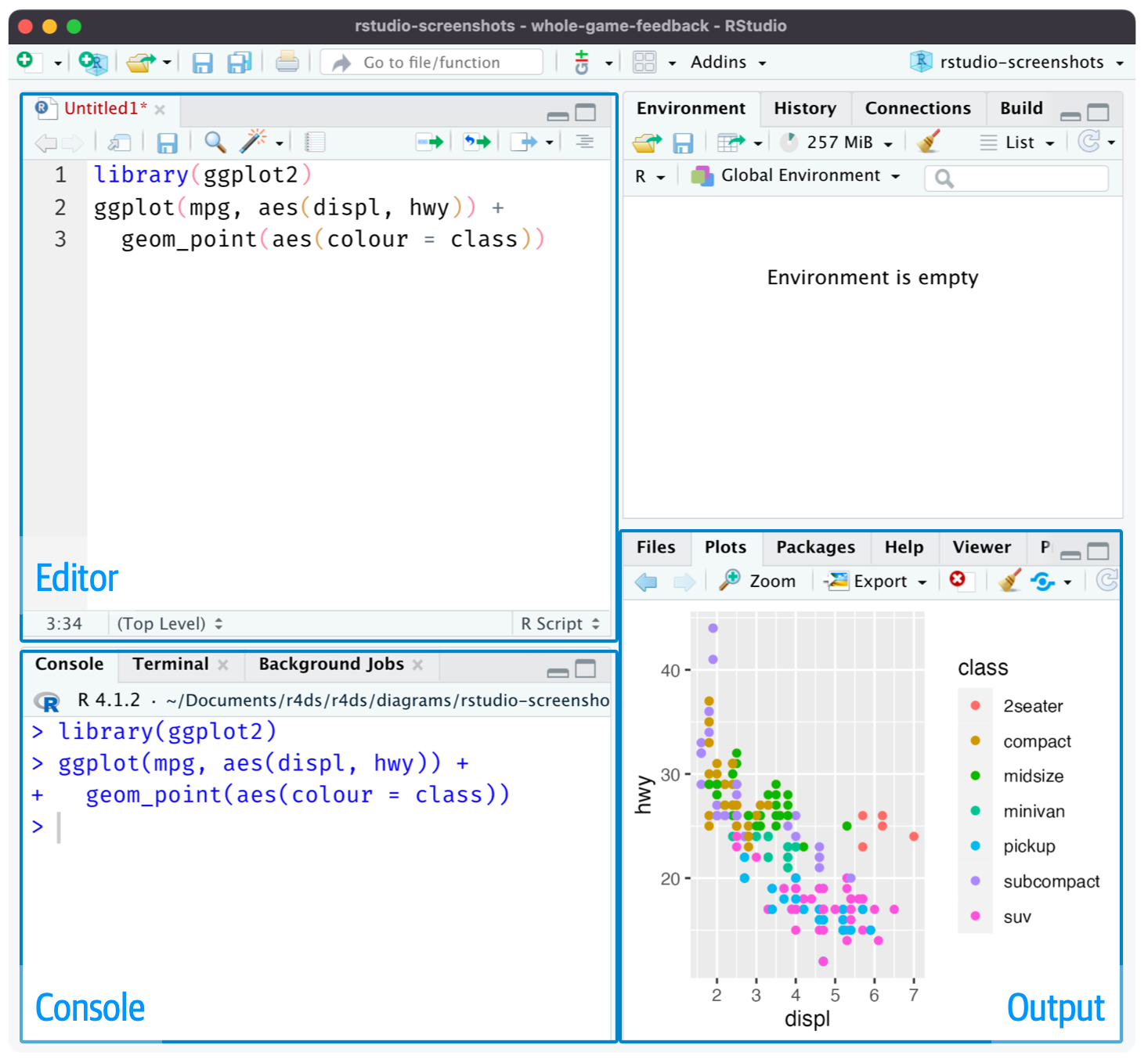
Interfaz de RStudio
El Tidyverse
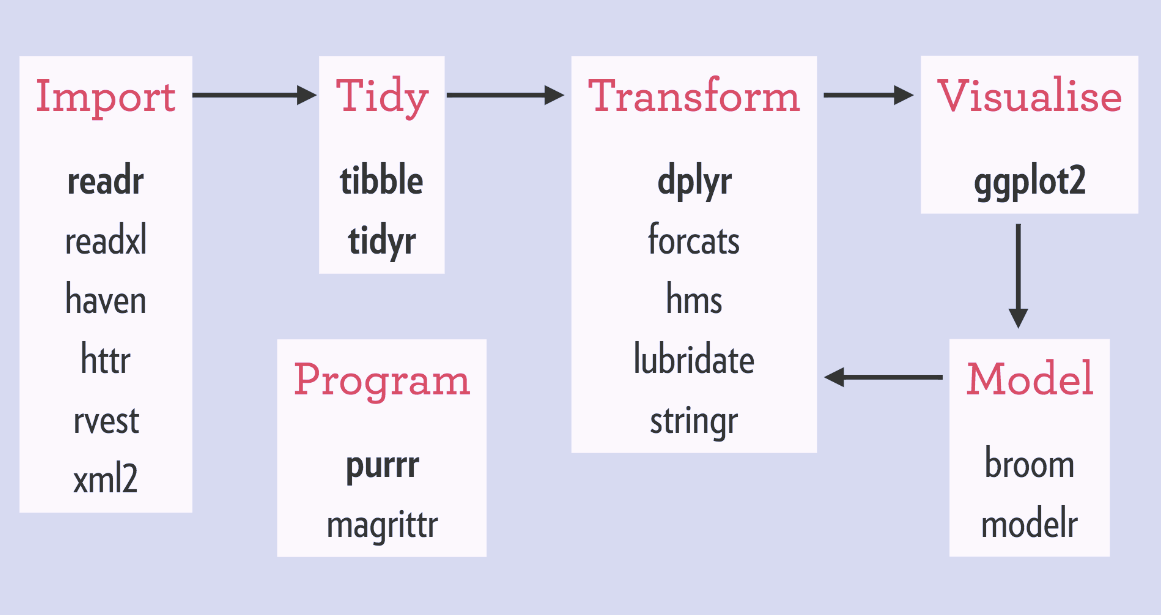
Para instalar el Tidyverse ejecutar el siguiente comando en la consola de R:
# Install from CRAN
install.packages("tidyverse")Diagnóstico de problemas
El editor resalta los errores de sintaxis con una línea roja serpenteante bajo el código y una cruz en la barra lateral1:
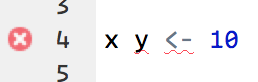
Para ver el problema ponemos el mouse sobre la cruz:

La importancia de crear un Proyecto
Un Proyecto es simplemente una carpeta para mantener todos los archivos asociados con un proyecto dado (datos, scripts, resultados, figuras) en el mismo lugar. Ventajas de hacer esto:
- Reproducibilidad
- Portabilidad
- Organización
- Se puede realizar fácilmente Control de Versiones
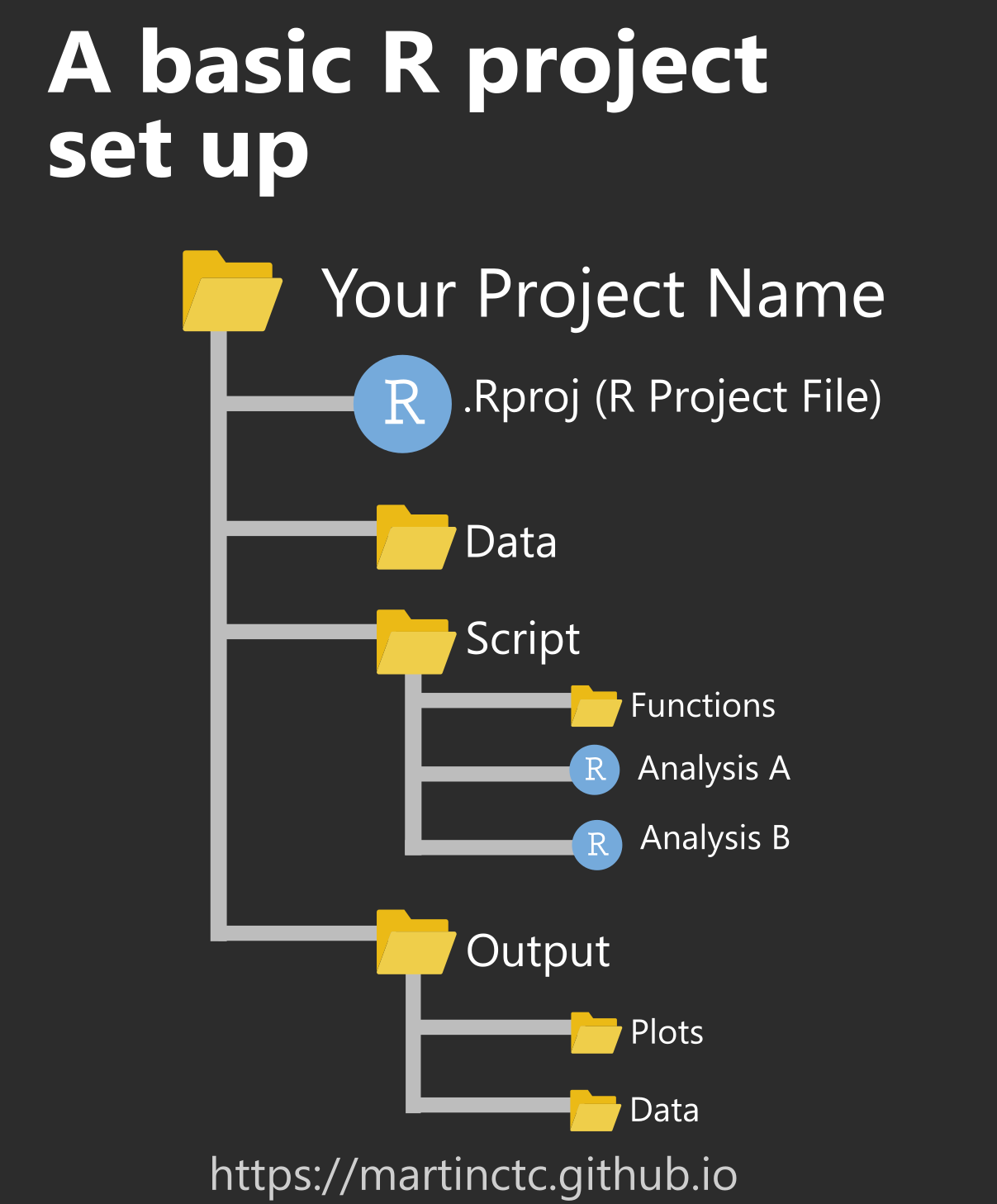
Reproducibilidad
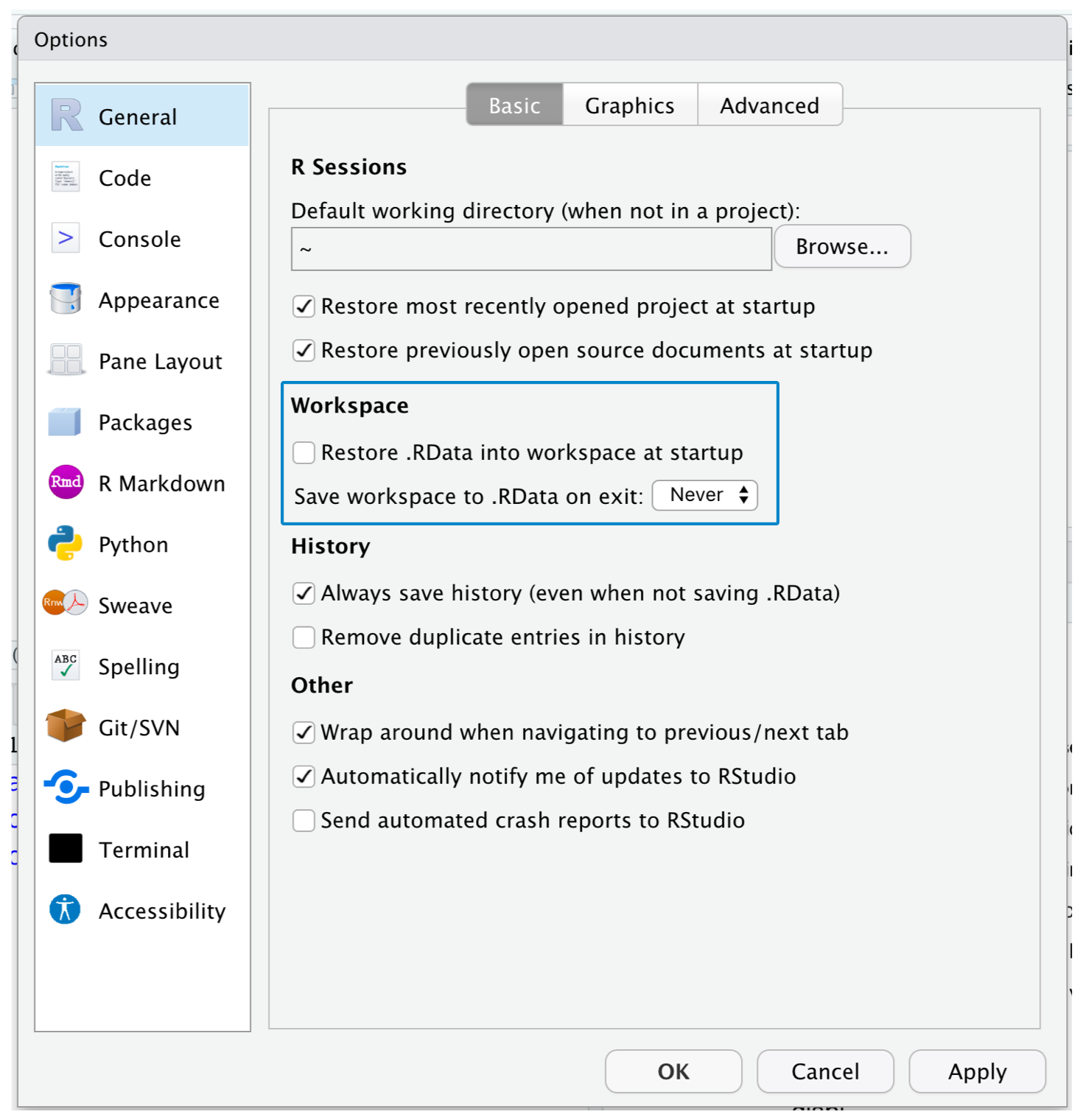
Solo con los scripts y los datos iniciales, cualquier persona debería ser capaz de reproducir tus análisis. Para fomentar el uso de scripts y que RStudio no recuerde información adicional sobre el ambiente de trabajo, es útil ajustar la configuración:
Los principios FAIR


Visualización de datos con ggplot2

Capas de ggplot2
Histogramas
ggplot(hojas) +
geom_histogram(mapping = aes(x = longitud))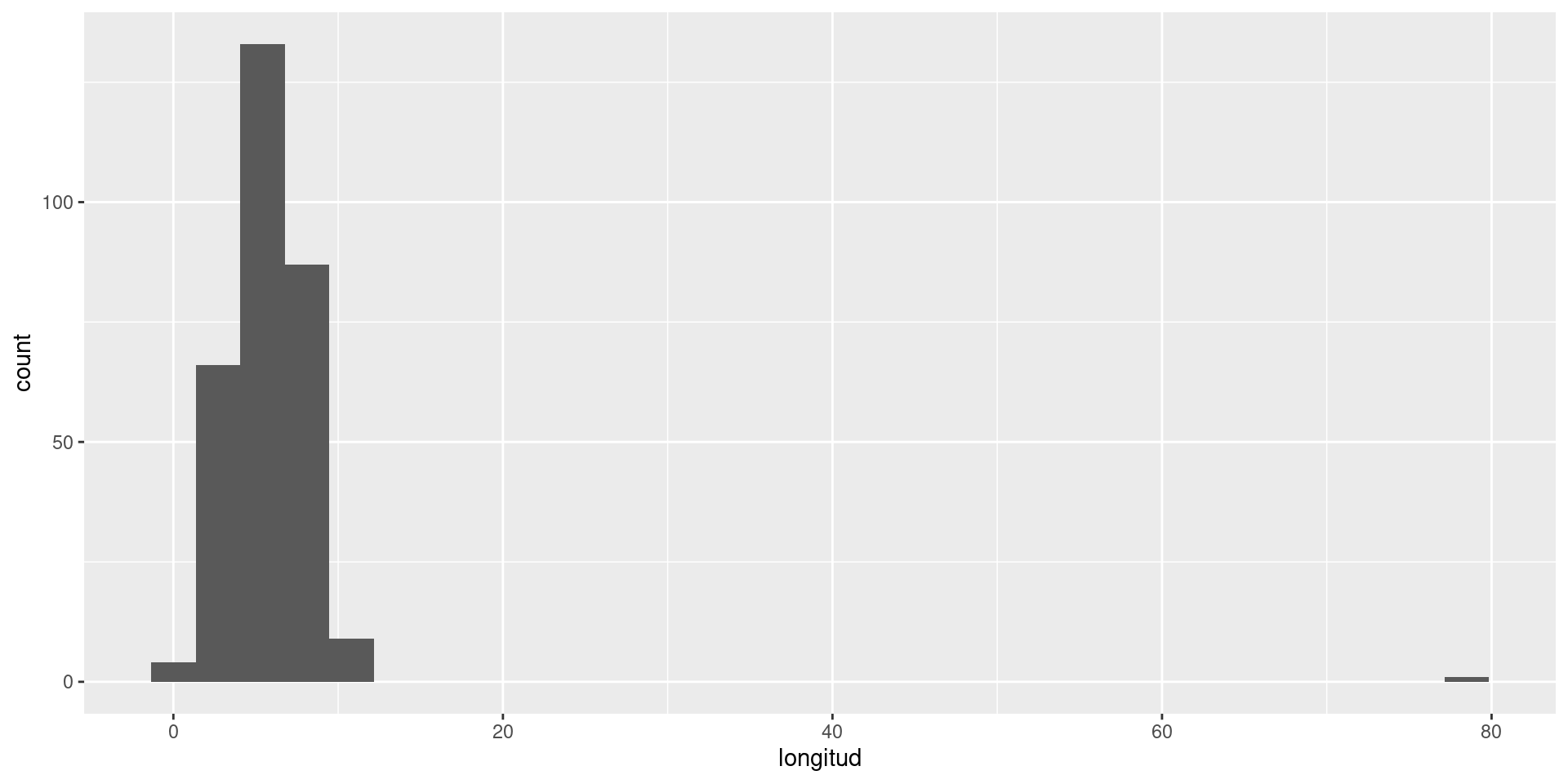
Boxplot o diagrama de caja
ggplot(hojas) +
geom_boxplot(mapping = aes(x = longitud))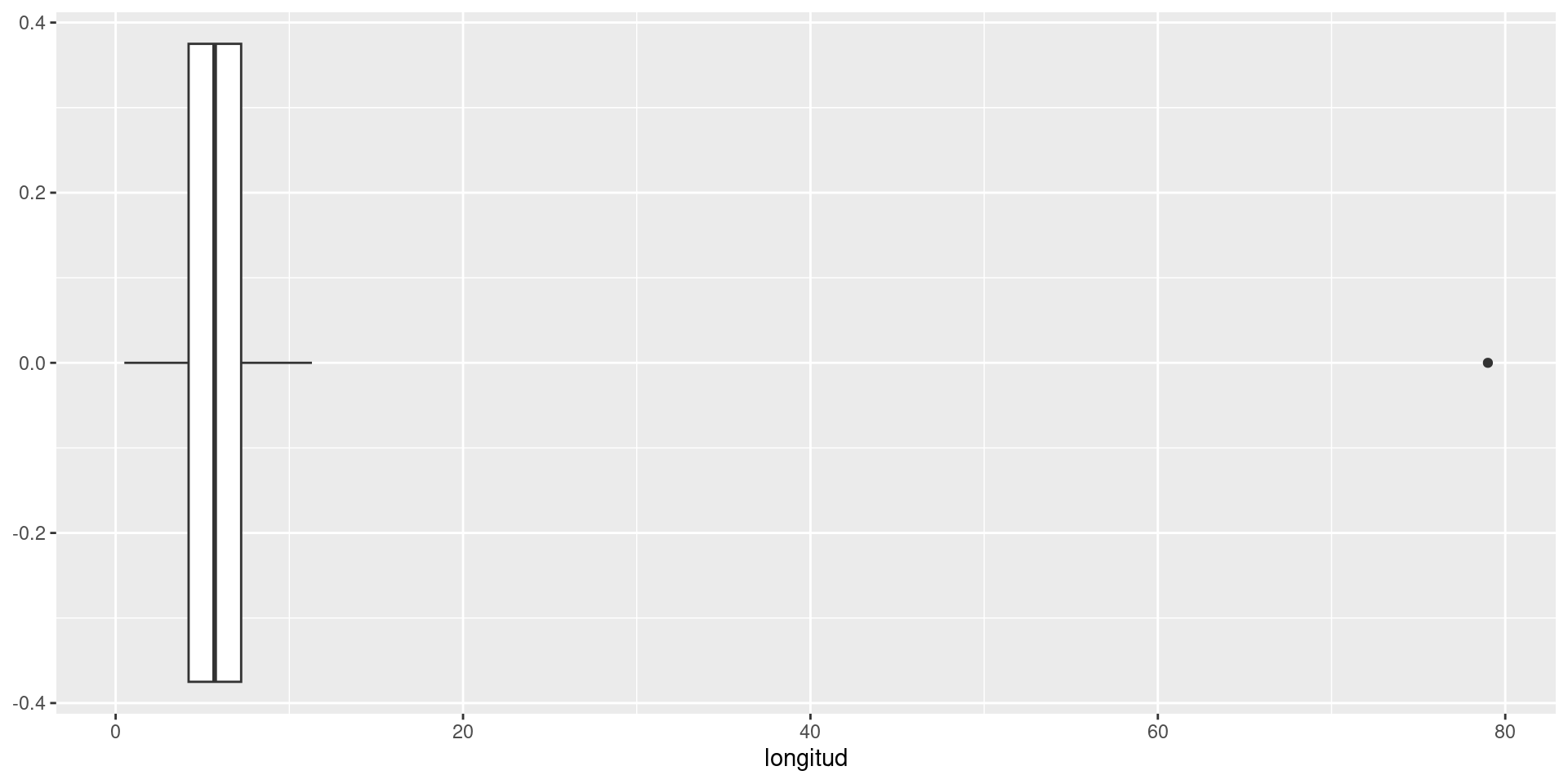
Density plot
ggplot(filtrados) +
geom_density(aes(x = longitud, y = after_stat(density)), fill = "#9999ff",
color = "#9999ff") +
annotate("text", x = 5, y = .1, label = "Longitud") +
geom_density(aes(x = ancho, y = -after_stat(density)), fill = "#77eeaa",
color = "#77eeaa") +
annotate("text", x = 2.5, y = -.2, label = "Ancho") + xlab('Medida en cm')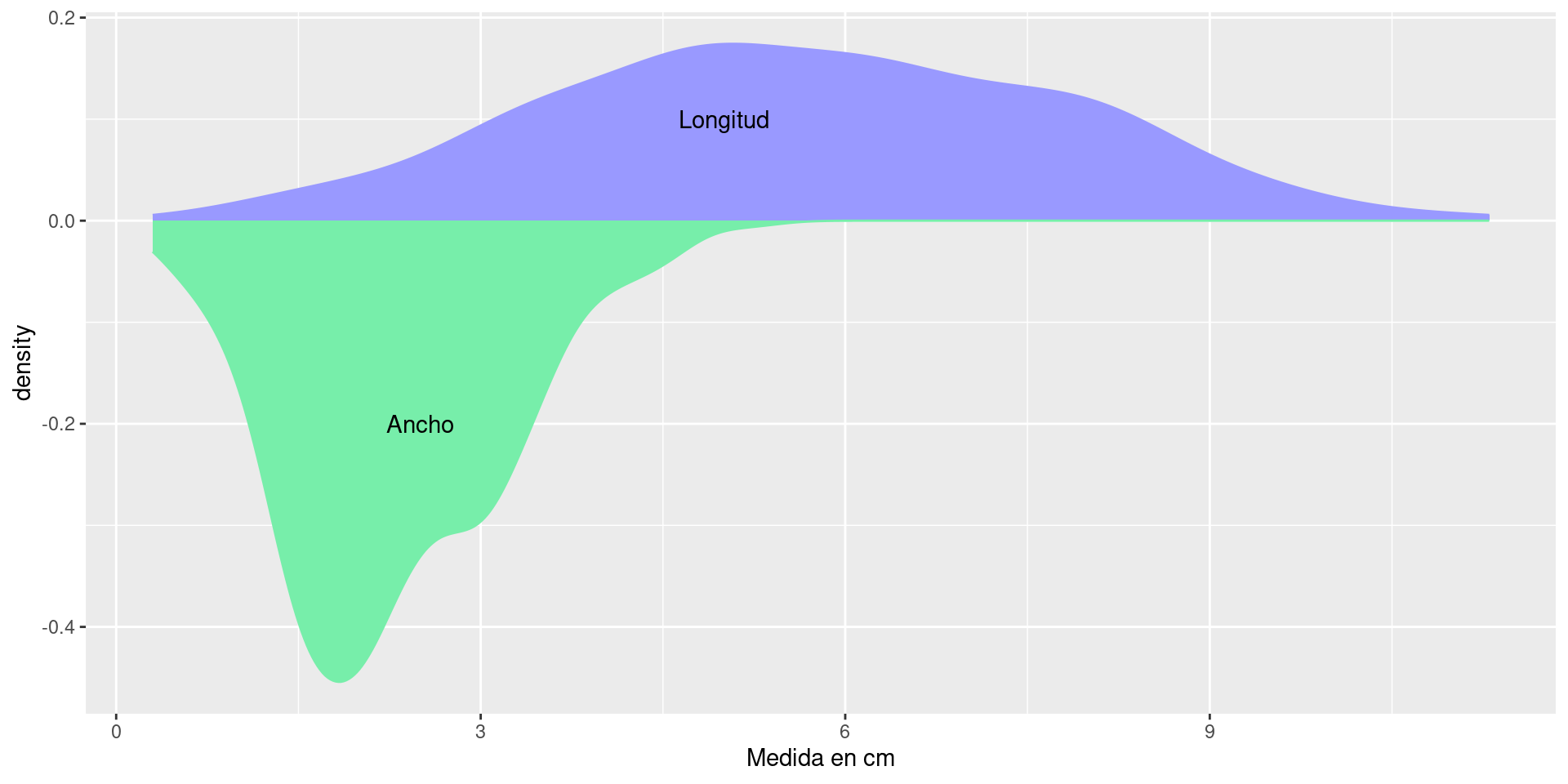
Gráficos de dispersión
ggplot(data = hojas) +
geom_point(mapping = aes(x = longitud, y = ancho, color = Científico))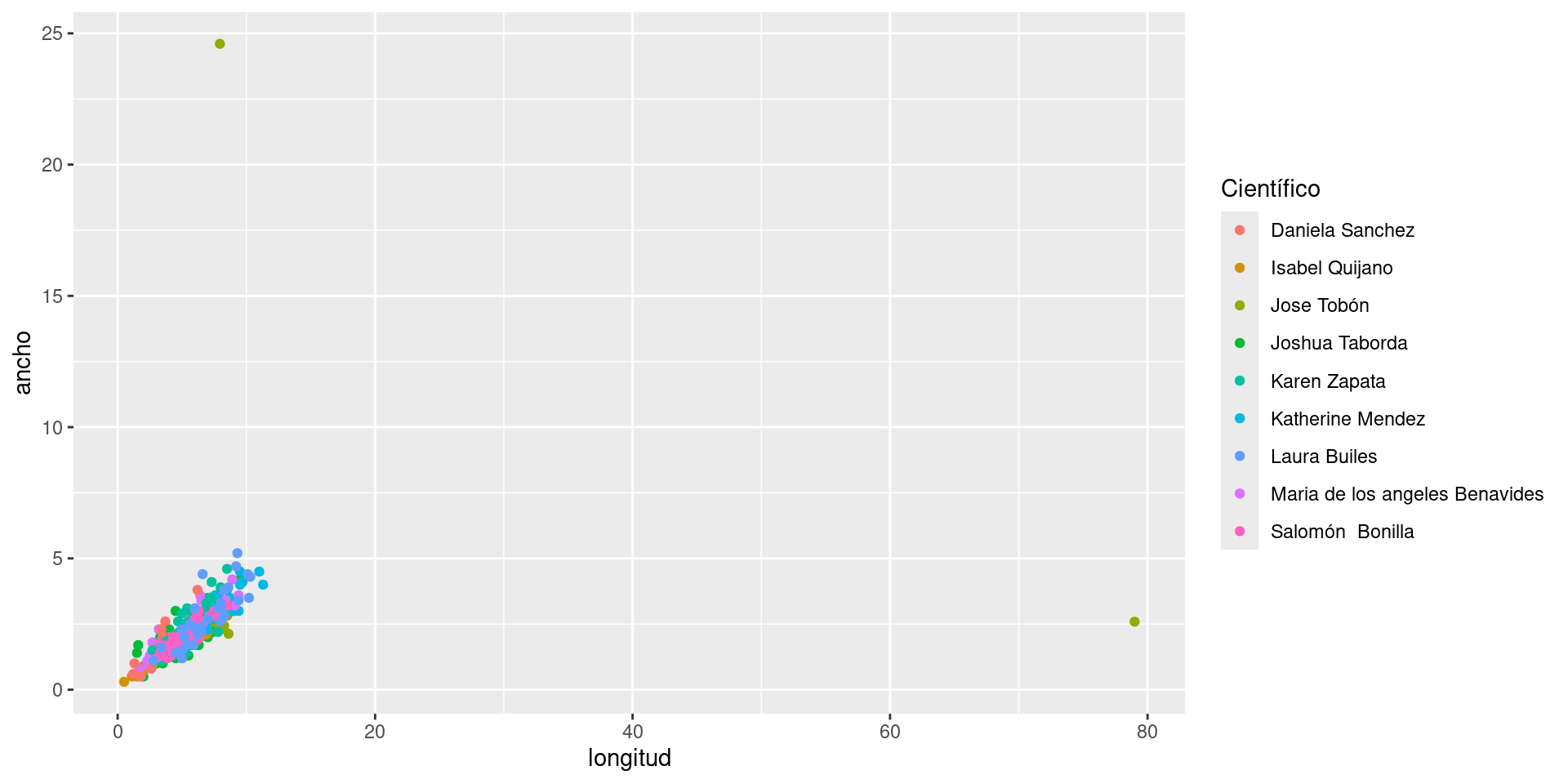
# Facetas
ggplot(data = hojas) +
geom_point(mapping = aes(x = longitud, y = ancho)) +
facet_wrap(~ Científico) +
xlim(NA, 12) +
ylim(NA, 5)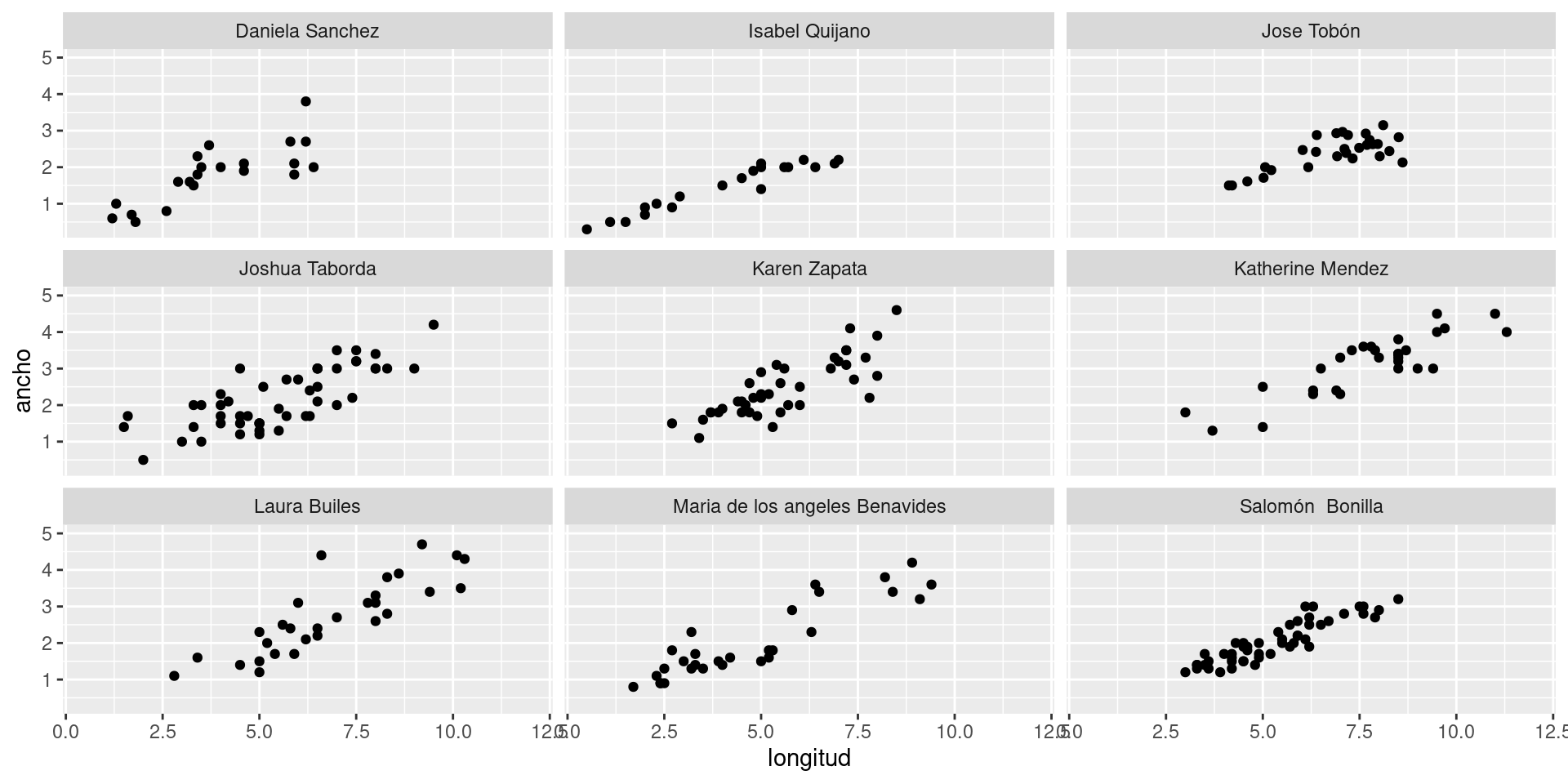
ggplot(data = hojas) +
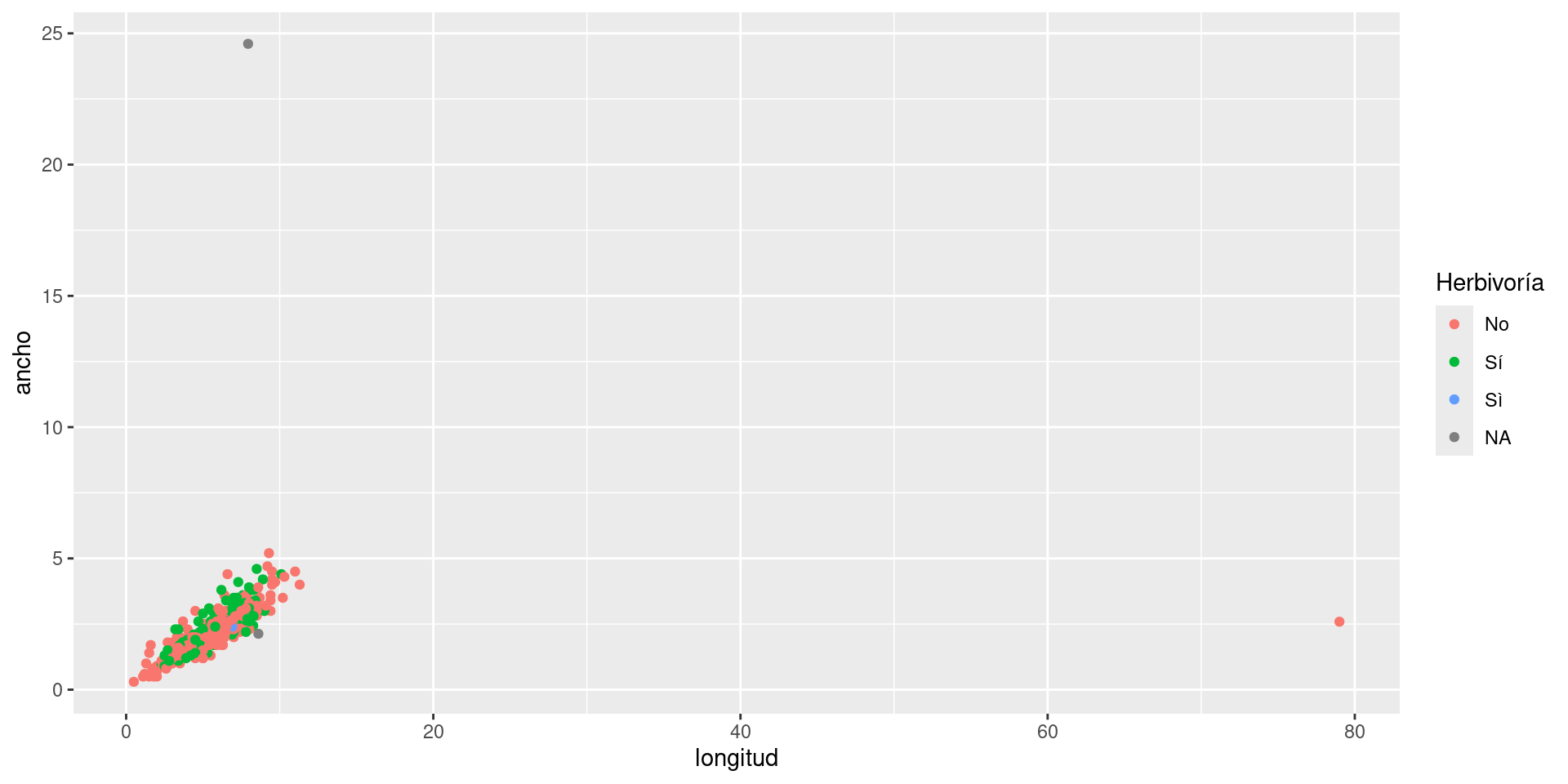
geom_point(mapping = aes(x = longitud, y = ancho, color = Herbivoría))